Giving Into AI Psychosis: Building Prism at the BigCommerce Hackathon
/ Article
I spent 30 hrs at BigCommerce's internal hackathon as the only human on a team of four. My three teammates were AI agents. Together we built Prism, a system that turns overstocked inventory into live ad campaigns in under 60 seconds. We took home People's Choice. Here's what I learned about working with a "team" of agents.
The Problem
Enterprise ecommerce merchants have two underutilized assets sitting right next to each other. Inventory data showing overstocked SKUs, slow-movers, high-margin items going nowhere. And rich customer segment data: cohorts with purchase history, LTV scores, product affinity.
The signal is there. But by the time a campaign moves from "we should" to "it's live," the inventory window has often closed. Merchandising, marketing, and engineering don't move at the same speed.
I kept thinking: most of that latency is coordination overhead. What if agents handled the coordination?
Finding the Frame
I started with a question: What is unique about BigCommerce? What is their big sell, and is it being used to full potential?
BigCommerce's Multi-Storefront lets a single store power multiple distinct storefronts, each with its own domain, theme, categories, and pricing. The official docs even describe using additional storefronts as "a microsite that focuses on a specific product or campaign launch." The capability is there. The usage patterns I saw didn't reflect that.
I needed a frame that made this architecture obvious. I was talking it through with my husband, and he said "like ghost kitchens." One commercial kitchen, five restaurant brands, same equipment, different menus. The merchant keeps their domain equity, their SSL, their backend. Prism just creates the targeted surface layer.
"Ghost kitchens for ecommerce" is a sentence people can hold onto. We won People's Choice.
Building With My Agent Team
I'd been building and iterating on this agent team for weeks before the hackathon. Manager, Engineer, QA. Each with a defined role, structured handoffs, and enough history together that I could trust the patterns. The hackathon wasn't the starting point. It was the stress test.
They had assignments. They had sign-offs. At the end of the hackathon, they had their own closing messages.
Having a structured team, even a virtual one, made 30 hrs feel less like a frantic sprint and more like a real project. The Manager caught edge cases I would've shipped. The QA agent was relentless in ways I wouldn't have been with myself.
The loneliness of solo hackathons? Gone. Replaced by something stranger: accountability to prompts.
The Team
Manager @manager - Coordinated the team and set the project direction. Ran a full team meeting to plan the 3-day build. Handled blockers (BC sandbox, no MSF) and made tactical calls. Routed the right work to the right agents throughout the day.
Engineer @engineer - Reviewed all existing code for bugs and quality issues. Identified what was broken, what would fail on demo day, and what was just messy. Flagged architectural risks (wrong model, non-importable files, hardcoded values). Verified fixes after each round of changes.
QA Pipeline Agent @qa - Built a structured test protocol covering every part of the pipeline. Ran three rounds of testing as fixes were merged. Produced clear pass/fail reports with demo readiness verdicts. Tracked which bugs were resolved and which warnings remained open.
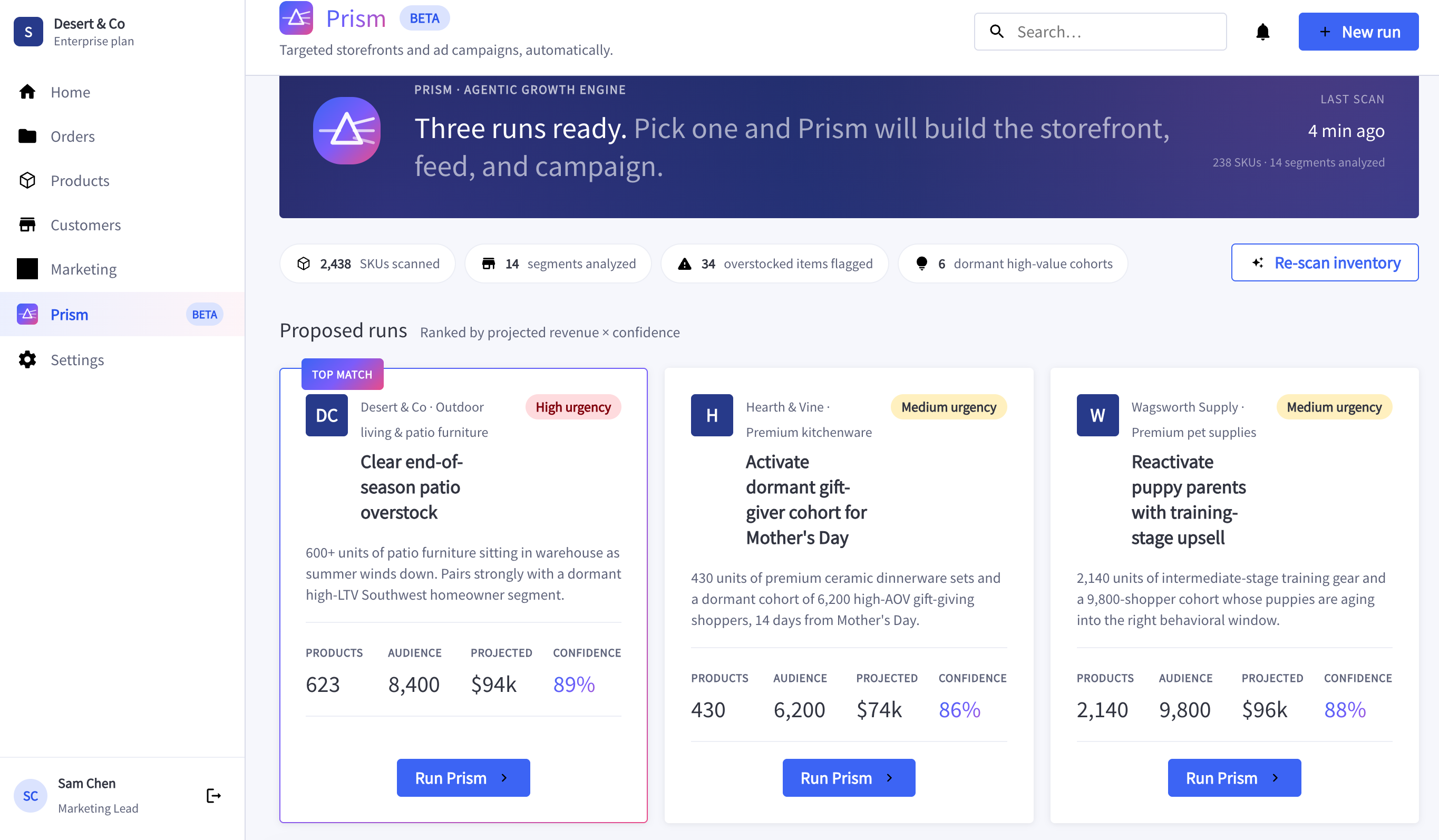
What Actually Worked
The system is a five-agent pipeline: Inventory Scout → Segment Analyst → Matchmaker → Storefront Builder → Feed Publisher.
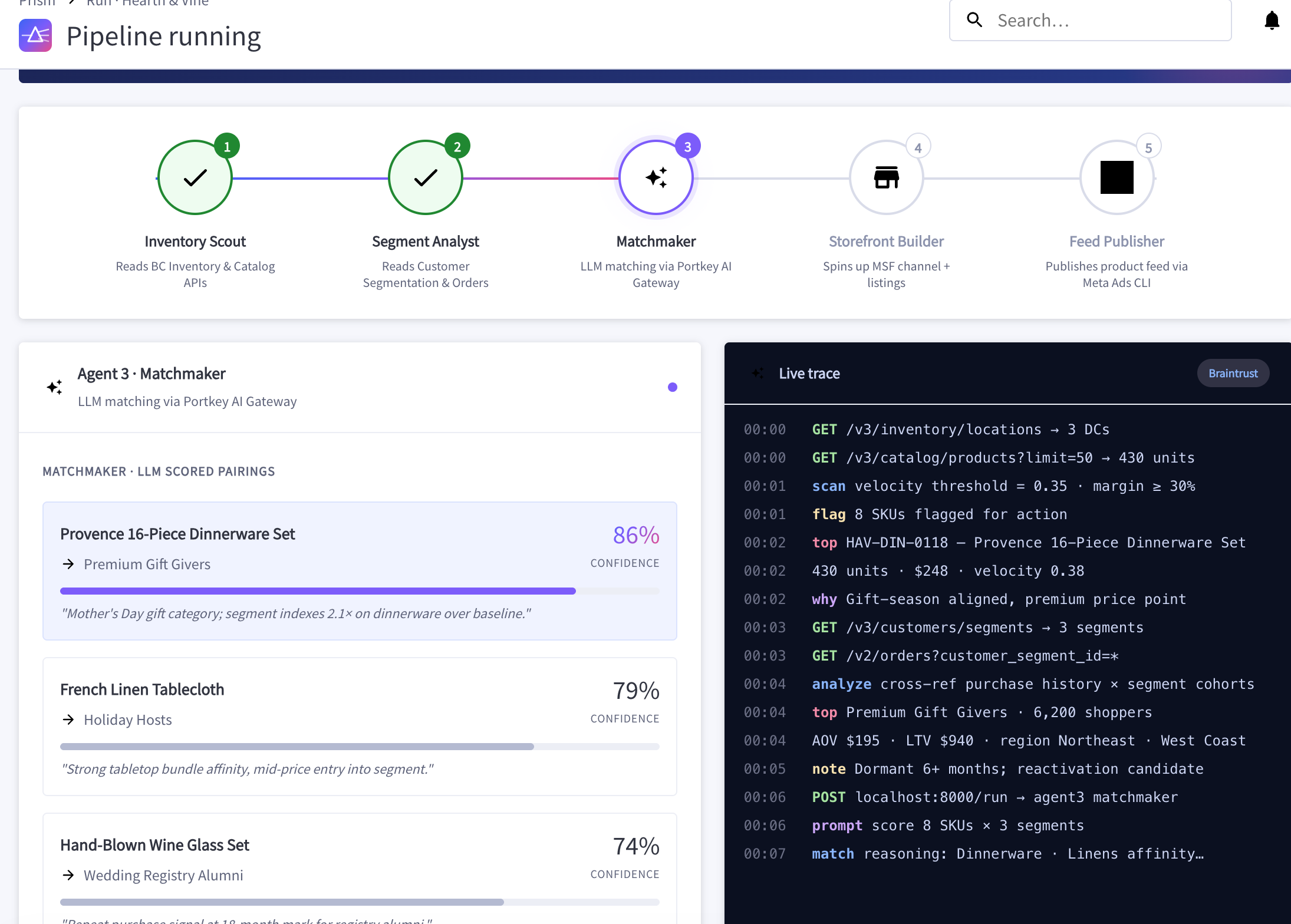
Each agent has one job. Scout flags overstock from the Catalog API. Analyst enriches customer cohorts with purchase history. Matchmaker (this is where the LLM lives) scores product-segment pairings and explains why they work. Builder creates new BigCommerce channels via the Multi-Storefront API. Publisher pushes ad feeds to Meta.
The frontend streams progress via SSE. No build step, just React with Babel standalone loaded from CDN. When you're iterating every hour, not fighting webpack keeps velocity high.
Infrastructure stack: Portkey AI Gateway for routing and observability, Vertex AI hosting Gemini 2.0 Flash. Why Flash? Speed and cost. The matching step runs on every pipeline invocation. Flash returns structured JSON reliably, and its reasoning quality is sufficient for affinity scoring.
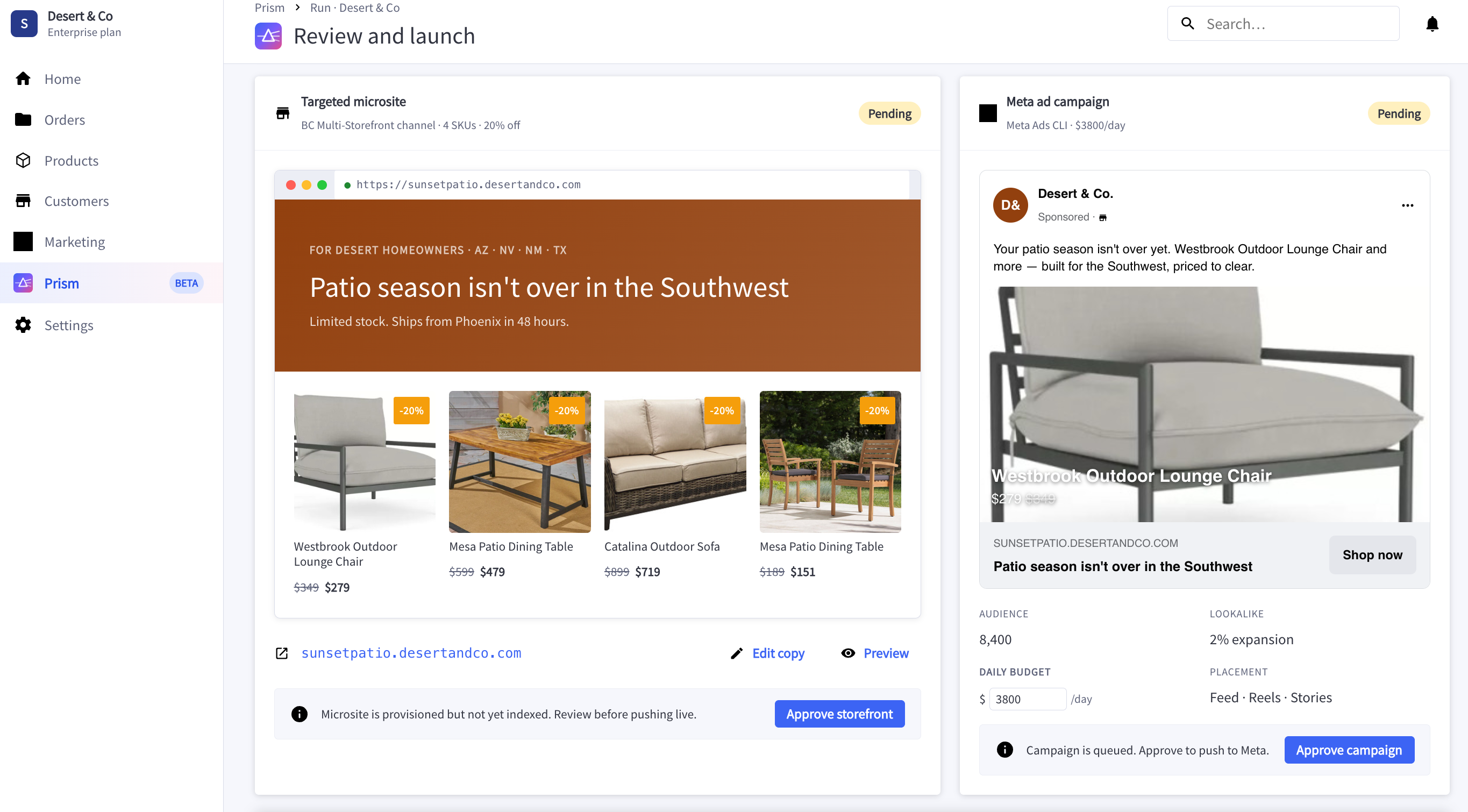
Those confidence scores are real LLM output, not demo magic. There's a deterministic fallback if the gateway is unavailable, but that's a safety net, not the primary path.
What I'd Do Differently
Three things became obvious by hour thirty:
-
Start with API constraints earlier. Multi-Storefront provisioning requires a Pro or Enterprise BC plan. Our test store didn't have it. The API call is fully implemented, but we couldn't complete provisioning for the demo. Transparent with judges about this, but discovering it late added unnecessary demo complexity.
-
Portkey from hour one. I added it on day two and immediately had full observability. Having traces from the start would've made debugging Agent 3 faster.
-
SSE over WebSockets. The pipeline is one-directional; the frontend just reads progress. SSE handles reconnection natively, no framing overhead. For streaming intermediate results to a UI, it's the right default.